
2.4 Applying the basic patterns¶
Now we will show a popular example, introduce a library called NumPy, and suggest a problem for you to solve by filling in some code.
Trapezoidal Rule Integration with Message Passing¶
This problem is also shown in Chapter 1, section 1.3, with a shared memory solution in OpenMP. The algorithm is a straightforward mathematical technique for finding the area under a curve by splitting the area into many small trapezoid slices whose area we can estimate, then add those areas together. This type of numerical integration is described on Wikipedia using the following diagram for an arbitrary function:

Consult the above Wikipedia entry for details on the mathematics for the composite trapezoidal rule, which is written into the function called trapSum() in the code below.
In our case, we will begin by considering the sine(x) function, which looks like this when x varies from 0 to \(5*\pi\):
We will use this function to make it simpler for us to determine the correctness of our parallel implementation in MPI. To make it even simpler, let’s first concentrate on the range of the first part of the above function, from 0 to \(\pi\), which looks like this:
We will rely on a mathematical theory which tells us that the integral where x ranges from 0 to \(\pi\) of sine(x) is 2.0. A sequential solution would split the curve of this function into many small trapezoids, iterating from a = 0.0 to b = \(\pi\), summing the value of each trapezoid as we go.
The code below illustrates how the trapezoidal integration example could be implemented with point-to-point communication. In this case, each process, including the conductor, splits up the computation among themselves using the parallel for loop pattern.
To visualize this, suppose we were using a small number of trapezoids (24) and 4 processes. We can decompose the work so that each process works on computing 6 of the trapezoids, like this, where each color represents a process:
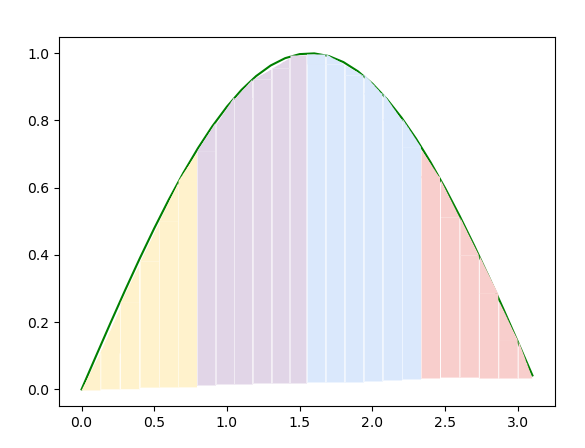
All of the processes add up the areas of their portion of the function, \(sine(x)\). Note that, as in the picture above, each process will determine its local range of values of x, my_a, and my_b. The workers send their ‘local’ sum to the conductor. Then the conductor waits to receive data from each of the other processes and combines the data received to calculate the final answer.
The trapSum() function computes and sums up a set of n trapezoids with a particular range. The first part of the main() function
follows the SPMD pattern. Each process computes its local range of trapezoids and calls the
trapSum() function to compute its local sum.
The latter part of the main() function follows the conductor-worker pattern. Each worker process sends its local sum to the conductor
process. The conductor process generates a global array (called results), receives the local sum from each worker process, and stores
the local sums in the results array. A final call to the sum() function adds all the local sums together to produce the final result.
Note
Notice lines 30, 36, and 37 in the code above. We use this technique to ensure that we can use any number of trapezoids and any number of processes, even if the trapezoids do not divide evenly among the processes. Compare this to the previous section, where we insisted that they divide evenly. Handling the case where we may have extras from non-even division of loops is a preferred parallel programming practice.
Try improving the result
This code is computing the integral from 0 to \(\pi\) of \(sine(x)\), which from mathematical theory should be 2.0. Notice the difference in the result if you increase the number of trapezoids, n on line 5 by multiplying it by 8, changing it to n = 1048576*8. Is this a better approximation of the result?
In later sections, we will see how to improve this example with other communication constructs. For now, ensure that you are comfortable with the workings of this program.
A Brief Aside: the numpy library¶
The mpi4py library of functions has several collective communication functions that are designed to work with arrays created using the Python library for numerical analysis computations called NumPy. Unlike Python lists, NumPy arrays hold only one type of data, and generally are faster and take up less space than Python lists that contain data of only one type.
NumPy arrays are specifically designed for fast mathematical computations and can be reshaped to form matrices and other multi-dimensional data structures. A detailed discussion of NumPy is beyond the scope of this book; for more about its features and available methods, we recommend consulting the documentation and available tutorials.
Since we do need some basic idea of how NumPy arrays work, however, let’s examine the following Python program that creates arrays in two different ways and displays them. We start with the import of numpy as np. Note how we make a point that some numpy functions expect their inputs to be certain types– for example, np.empty() takes an integer for the length of a new array to create.
After running this example, compare the code to the output. Observe that numpy library arrays have these characteristics:
Arrays are created to have a given length.
Arrays always contain values of a certain numerical type.
We use syntax like this to access the ith value of an array: npArray[i]
Exercise - Populate an Array¶
As an exercise, let’s use point-to-point communication to populate an array in parallel. Suppose we want to generate an array of N values from 1 to N. For typical real problems, N is large and may have a random pattern of values. But to visualize what you need to do for this simpler version, if N was 9 and we had 3 processes, each process could create part of the desired final array in local arrays like this:
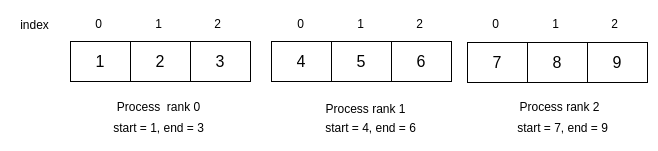
Once each worker process has created its local portion of the overall array, it can send that to the conductor, who will place it in the proper location in a global array of length 9 that it has created.
Note
The important points about coding a correct solution for p processes are
The local array in each process contains N/p values, thus its length is an integer equal to N/p.
We use the process rank and the number of elements in each local array to determine its start value and end data values, which will be integers. Take the time now to determine how to compute a start and end data value.
In case N is not divisible by p, the last process can create N%p extra values. This technique will also be used in later sections of this chapter.
Use what you have seen in the previous examples to determine how to split up the loop in the populateArray function below. The algorithm is as follows
Each process computes its local range of values by calling a
populateArrayfunction that generates an array of just those values.
Each process populates an array of N/p values, where p is the number of processes. In other words, the number of elements (nElems) in each local array is N/p.
Each process determines its start and end values and length of their array:
Process 0 generates values 1 through nElems,
Process 1 generates values nElems+1 through 2*nElems
etc. for each process chosen
Each worker process sends its array to the conductor process.
The conductor process generates a global array of the desired length, receives the local array from workers, and then populates the global array with the elements of the local arrays received.
The final global array on the conductor has N values, simply holding all values from 1 to N.
The following program is a partially filled in solution, with the parts to complete shown in comments with TODO beside them. If you are stumped, a solution is hidden below.
Fill in the rest of the program, test your program using 1, 2, 3, and 4 processes. For initial debugging, you might want to temporarily change N to a small number like 9 and print out the local arrays in each process and the global array on the conductor.
Remember, in order for a parallel program to be correct, it should return the same value with every run, regardless of the number of processes chosen. Click the button below to see our solution.
Warning
If you have errors in your code, you may simply get output that looks like this:
===== NO STANDARD OUTPUT =====
===== NO STANDARD ERROR =====
You will need to try a fix. It is best to work on each TODO task, perhaps adding a debug print, try running to be sure you haven’t introduced an error before you go on.
Solution¶
The following program demonstrates how to implement the populateArray program. Make sure you try to solve the exercise yourself before looking at the solution!