
Program Structure: SPMD, Conductor-Worker, and Parallel Loops¶
This initial set of MPI pattern examples illustrates how many distributed processing programs are structured. For this examples it is useful to look at the overall organization of the program and become comfortable with the idea that multiple processes are all running this code simultaneously, in no particular guaranteed order.
00. Single Program, Multiple Data¶

First let us illustrate the basic components of an MPI program, which by its nature uses a single program that runs on each process. Note what gets printed is different for each process, thus the processes using this one single program can have different data values for its variables. This is why we call it single program, multiple data (SPMD). This pattern is in the overall pattern diagram and is shown on the left.
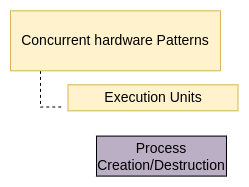
The call to MPI_INIT on line 11 tells the MPI system to setup. This includes allocating storage for message buffers and deciding the rank each process receives. MPI_INIT also defines a communicator called MPI_COMM_WORLD. A communicator is a group of processes that can communicate with each other by sending messages. The MPI_Finalize command tells the MPI system that we are finished and it deallocates MPI resources. From the patterns diagram, these built-in MPI functions carry out the pattern for the box shown at left.
To do:
Compare the source code to output when you run it.
Rerun, using varying numbers of processes (i.e., vary the argument to ‘-np’).
Explain what “multiple data” values this “single program” is generating.
Note
All MPI programs employ the single program, multiple data program structure. Notice how we have one program and all processes run that same program. Each process has different data for its id and possibly its hostname, depending on whether the program is running on a cluster of different hosts or a single host.
To Consider:
Can you determine the purpose of the MPI_Comm_rank function and MPI_Comm_size function? How is the communicator related to these functions?
01. The Conductor-Worker Implementation Strategy Pattern¶
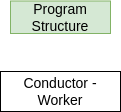
The conductor-worker pattern is illustrated in this simple example. The pattern consists of one process, called the conductor, executing one block of code while the rest of the processes, called workers, are executing a different block of code. This pattern is the box on the left in the patterns diagram, under Program Structure, which is under Parallel Implementation Strategy Patterns.
To do:
Compile and run the program, varying N from 1 through 8.
Observe what stays the same and what changes as the number of processes changes.
02. Data Decomposition: on equal-sized chunks using the parallel for loop pattern¶
The data decomposition pattern occurs in code in two ways:
1. A for loop that traverses many data elements stored in an array (1-dimensional or more). If each element in an array needs some sort of computation to be done on it, that work could be split between processes. This classic data decomposition pattern divides the array into equal-sized pieces, where each process works on a subset of the array assigned to it.
2. A for loop that simply has a total of N independent iterations to perform a data calculation of some type. The work can be split into N/P ‘chunks’ of work, which can be performed on each of P processes.
In this example, we illustrate the second of these two. The total iterations to perform are numbered from 0 to REPS-1 in the code below. Each process will complete REPS / numProcesses iterations, and will start and stop on its chunk from 0 to, but not including REPS. Since each process receives REPS / numProcesses consecutive iterations to perform, we declare this an equal-sized chunks decomposition pattern.
Note
But wait! As you can guess, in most code we cannot always get equal-sized chunks for all processes- the REPS is not equally divisible by the numProcesses. We can instead distribute chunks that differ by no more than one in size. Study the code to see how this is done and try the suggestion for running it below.
To Consider:
Verify that the program behavior is as follows for 4 processes:
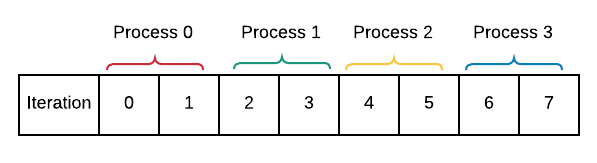
To do:
Run it more than once- what do you observe about the order in which the processes print their iterations?
Try it for other numbers of processes from 1 through 8.
When the REPS are equally divisible by the number of processes (e.g. 2, 4, or 8 processes), the work is equally distributed among the processes. What happens when this is not the case (3, 5, 6, 7 processes)?
Also try changing REPS to be larger and an odd number. Does it continue to behave as you might expect? Sketch a diagram as above for how 12 reps get distributed to 5 processes.
Note
This is a basic example that does not yet include a data array, though it would typically be used when each process would be working on a portion of an array that could have been looped over in a sequential solution.
03. Data Decomposition: on chunks of size 1 using parallel for loop¶
A simple decomposition sometimes used when your loop is not accessing consecutive memory locations would be to let each process do one iteration, up to N processes, then start again with process 0 taking the next iteration. The processes perform parts of the loop like this:
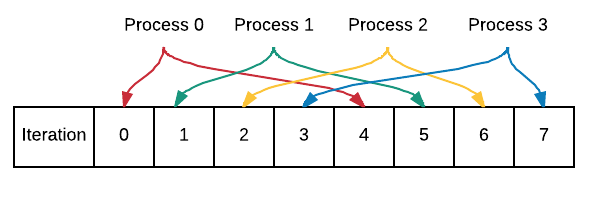
Run the code to verify the above depiction of processes to iterations.
To Consider:
A for loop on line 17 is used to implement this type of data decomposition. How does it differ from the for loop in the ‘equal chunks’ example above?
To do:
Run by varying -np: 1, 2, 3, 4, 5, 6, 7, 8
Change REPS to 16, save, recompile, rerun, varying -np again.
Explain how this pattern divides the iterations of the loop among the processes.
Note
An important take-away point of these last two examples is that data decomposition can occur in two different ways: splitting into almost equal chunks of work, or single units of work. They key coding aspect of this is how the for loops are constructed.