
5.2 Broadcast and Data Decomposition with Parallel for Loop¶
We now expand upon data decomposition using parallel-for loop with equal-sized chunks to incorporate broadcast and gather. We begin by filling an array with values and broadcasting this array to all processes. Afterwards, each process works on their portion of the array which has been determined by the equal sized chunks data decomposition pattern. Lastly, all of the worked on portions of the array are gathered into an array containing the final result. Below is a diagram of the code executing using 4 processes. The diagram assumes that we have already broadcast the filled array to all processes.
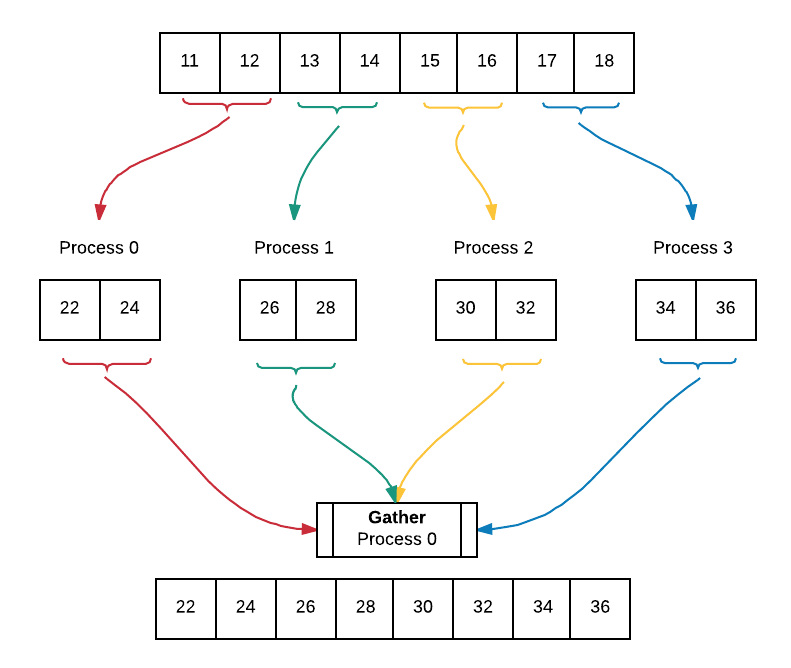
Note that we chose to keep the original array, array, intact. Each process allocates memory, myChunk to store their worked on portion of the array. Later, the worked on portions from all processes are gathered into a final result array, gatherArray. This way of working on array is useful in instances in which we want to be able to access the initial array after working on it.
Exercise:
Run using 2, 4, and 8 processes
Use source code to trace execution and output
Why do you observe different output when you run it several times?
Explain behavior/effect of MPI_Bcast(), MPI_Gather().
Verify that the original array on each process has not changed by uncommenting the print() call in main
optional: change MAX to be another multiple of 8, such as 16
5.3 Scatter, Data Decomposition with Parallel for Loop, then Gather¶
Recall this image from the previous example:
In that example the conductor process broadcast the entire array to all processes. In this next example, we will instead illustrate how to scatter the original array so that every process has a portion of it. Then the same computation on each process will occur, and the portions will be gathered back together onto the conductor process.
Exercise:
Run, using 1, 2, 4, and 8 processes
Use source code to trace execution and output
Explain behavior/effect of MPI_Scatter(), MPI_Gather().
Optional: change ARRAY_SIZE to be another multiple of 8, such as 16
Optional: eliminate calls to print() to display each array at each step, keeping only the final gatherArray
5.4 Scatter and Gather with any size array and odd or even number of processes¶
In the previous two examples, we needed to ensure that the array size was divisible by the number of processes. Since this is often not the case in a normal application, MPI has functions that enable us to scatter and gather variable-sized ‘chunks’ of our arrays. We still need to ensure that the number of processes is less than the array size.
The functions we will use for this are called MPI_Scatterv and MPI_Gatherv. We will use a way of splitting the arrays into nearly equal sized chunks that we demonstrated in example 02 of the program structure section of the previous chapter.
In the code below, the call to MPI_Scatterv looks like this:
MPI_Scatterv(scatterArray, chunkSizeArray, offsetArray, MPI_INT,
chunkArray, chunkSize, MPI_INT,
CONDUCTOR, MPI_COMM_WORLD);
Note
These new functions take new second and third arguments that are arrays of integers designed to show how to split the original data array. The conductor process uses these arrays to send a portion to each worker process. As with all coordination functions, all processes must call this function.
The second and third arguments are arrays whose size is the same as the number of processes. The values at index 0 are for process 0, index 1 for process 1, and so on. The second argument is an array that contains the total number of elements to be scattered to each process, and the third argument is the offset into the original array where the chunk to be given to that process is.
The code for setting up these arrays is very similar to how we set up nearly equal sized chunks for decomposition using the for-loop pattern, and looks like this:
// find chunk size for part of processes
int chunkSize1 = (int)ceil(((double)ARRAY_SIZE) / numProcs);
int chunkSize2 = chunkSize1 - 1;
int remainder = ARRAY_SIZE % numProcs;
// compute chunkSize and offset array entries for each process
for (int i = 0; i < numProcs; ++i) {
if (remainder == 0 || (remainder != 0 && i < remainder)) {
chunkSizeArray[i] = chunkSize1;
offsetArray[i] = chunkSize1 * i;
} else {
chunkSizeArray[i] = chunkSize2;
offsetArray[i] = (remainder * chunkSize1) + (chunkSize2 * (i - remainder));
}
}
Suppose that the data array is set to have 10 elements and we use 3 processes. After the data is initialized by the conductor and the above code is executed, the status as we call MPI_Scatterv looks like this:
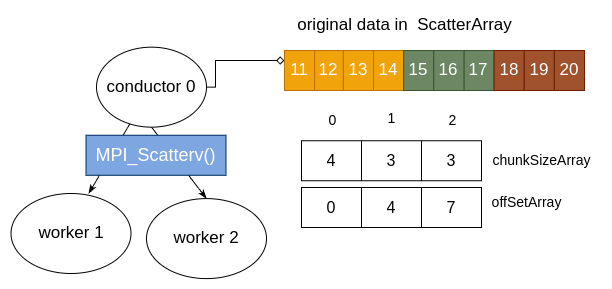
Then after MPI_Scatterv has completed, the arrays on each process would look like this:
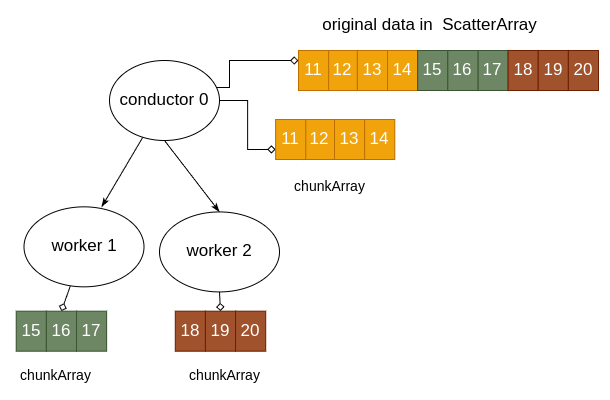
The complete code is below so that you can run it. It also contains a call to MPI_Gatherv that enables the conductor process to gather all of the computed values back into a separate array.
Exercise:
Compile and run, using 1, 2, 3, 4, 5, and 10 processes
Use source code to trace execution and output
Explain behavior/effect of MPI_Scatterv() and Gatherv()
Optional: change ARRAY_SIZE