
Parallel Programming Patterns¶
Like all programs, parallel programs contain many patterns: useful ways of writing code that are used repeatedly by most developers because they work well in practice. These patterns have been documented by developers over time so that useful ways of organizing and writing good parallel code can be learned by new programmers (and even seasoned veterans). We believe that seeing code demonstrating the patterns helps you learn how and when to use them.
The concepts described in this chapter are derived from the following sources created by researchers in the field of parallel computing who pioneered the theory and concept of organizing parallel programming patterns.
Mattson, Timothy G., Beverly Sanders, and Berna Massingill. Patterns for parallel programming. Pearson Education, 2004. This book started the movement.
This was followed by Our Pattern Language, based on this paper:
Keutzer, Kurt, and Tim Mattson. “Our Pattern Language (OPL): A design pattern language for engineering (parallel) software.” ParaPLoP Workshop on Parallel Programming Patterns. Vol. 14. 2009.
Then both groups combined efforts in this paper:
Keutzer, Kurt, et al. “A design pattern language for engineering (parallel) software: merging the PLPP and OPL projects.” Proceedings of the 2010 Workshop on Parallel Programming Patterns. 2010.
An organization of parallel patterns¶
We introduce the following diagram that organizes some, but not all patterns mentioned in the above books, papers, and sites. We also add notions of what types of hardware are associated with some patterns and in what software libraries some of these patterns are found.
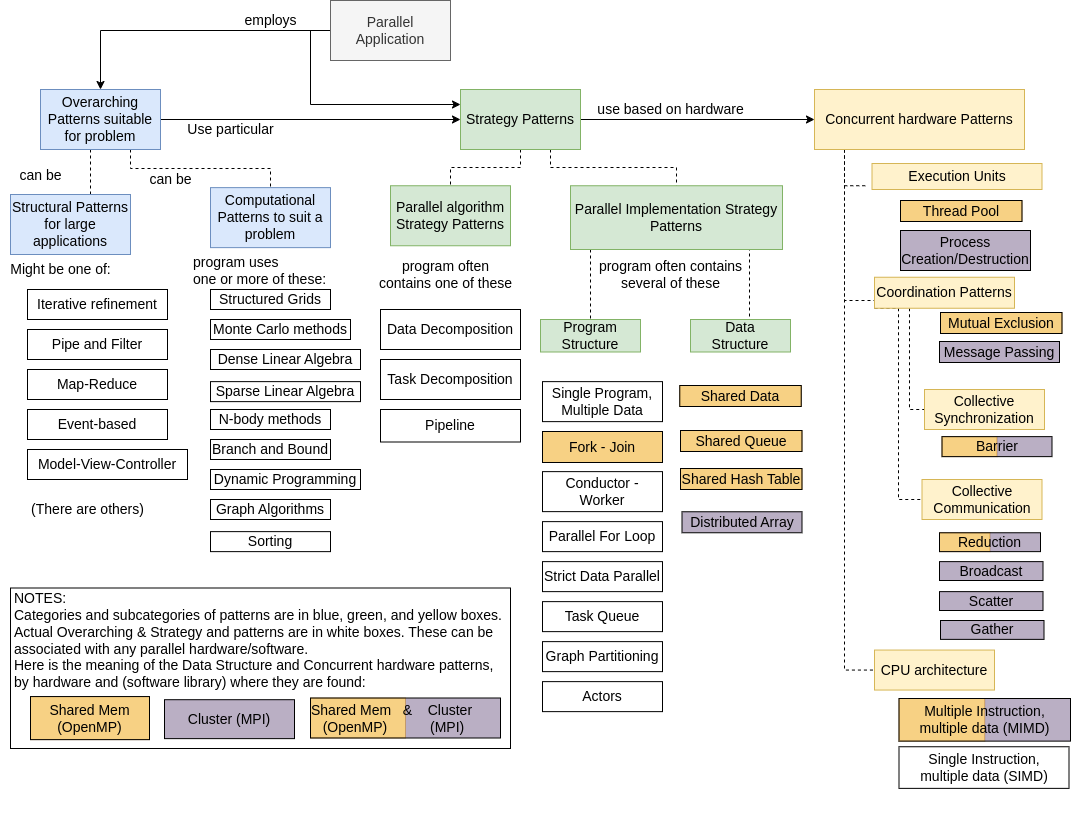
We will break down portions of this diagram as we continue our discussion here and as we introduce code examples that use them in subsequent chapters. So if it seems large and daunting, fear not - we will work through smaller portions. Let’s start from the top with the categories of patterns:
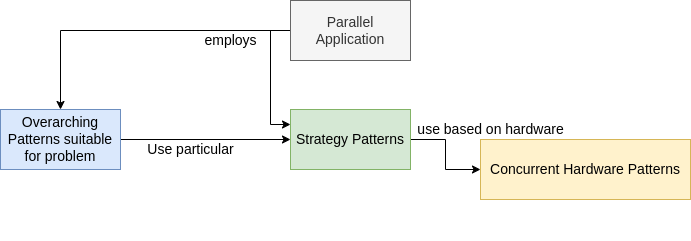
When writing parallel programs, developers often start from an application that was written for execution on one processor (a sequential, or serial program), though sometimes they are starting from scratch. Regardless, they work through the categories shown above as they transform their application to take advantage of parallel and distributed computing hardware.
As this portion of the overall diagram indicates, developers first determine the overarching patterns that are suitable to solve the problem (blue box). We will not delve into these right now, but leave them until later when we look at full applications that use them. One example (of many) of these is linear algebra operations, such as matrix multiplication. Next, the overarching patterns chosen for an application must then be implemented using parallel strategy patterns (green box) and concurrent hardware patterns (yellow box), which stem from the particular hardware that will be used. Here we will focus on two types of hardware: shared memory machines with multicore CPUs, and distributed systems that use multiple machines networked together (often referred to as clusters).
We will initially concentrate on these two categories of patterns used in parallel programs in subsequent chapters of this book.
Strategies
Concurrent Hardware
As you will see in code examples, many of the patterns in these categories are now built into the software libraries that developers use for parallel programming:
OpenMP on Shared Memory machines and
Message Passing Interface (MPI) on clusters OR shared memory machines.
Strategy Patterns¶
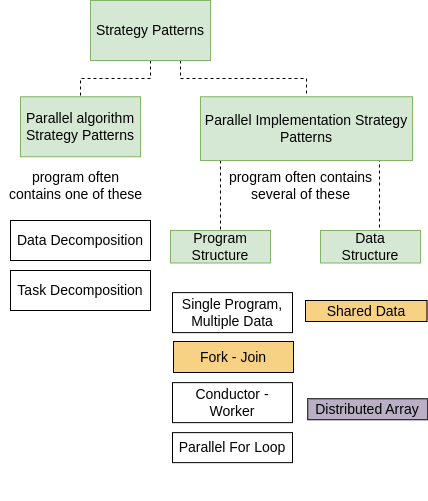
When you set out to write a program, whether it is parallel or not, you should be considering two primary strategic considerations:
What algorithmic strategies to use
Given the algorithmic strategies, what implementation strategies to use
In the examples in the next two chapters we introduce these well-used patterns for both algorithmic strategies and implementation strategies, which are a subset of those shown in the complete patterns diagram introduced earlier.
Parallel algorithmic strategies primarily have to do with making choices about what tasks can be done concurrently by multiple processing units executing concurrently. Parallel programs often make use of several patterns of implementation strategies. Some of these patterns contribute to the overall structure of the program, and others are concerned with how the data that is being computed by multiple processing units is structured. Those data structure patterns are more likely to go hand-in-hand with the hardware and software library being used to implement the program, so that is indicated in the above diagram, where shared data in orange goes with Shared memory machines using OpenMP, and Distributed data goes with clusters using MPI (see below for further detail).
Concurrent Hardware patterns¶
We will concentrate on examples of two types of concurrent hardware used in parallel and distributed (PDC) computing:
Shared memory multicore CPU machines.
Clusters of networked machines.
Note
The most important concept to realize at this point is that these two types of hardware use two fundamentally different underlying operating system mechanisms that affect the patterns that you will see. These are threads and processes.
Shared memory system programming on multicore machines use threads as the concurrent processing unit that enables parallel simultaneous execution in portions of a program.
Clusters use processes as the concurrent processing unit that enables parallel simultaneous execution in portions of a program.
Shared memory machines can also use processes as the concurrent processing unit.
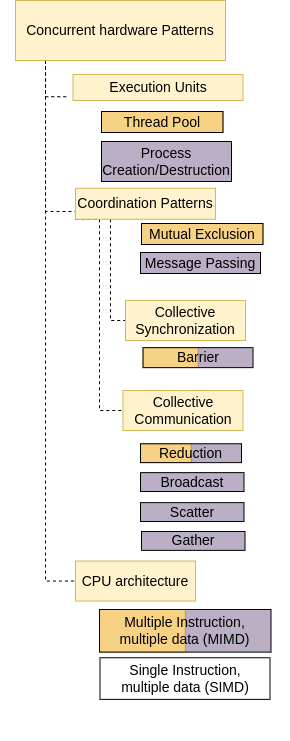
There are a number of parallel code patterns that are closely related to the system or hardware that a program is being written for and the software library used to enable parallelism, or concurrent execution. These concurrent hardware patterns, depicted above, fall into three major categories:
Execution Units patterns, which dictate how the processing units of parallel execution on the hardware (either a process or a thread, depending on the hardware and software used) are controlled at run time. For the patternlets described in this book, the software libraries that provide system parallelism have these patterns built into them, so they will be hidden from the programmer.
Coordination patterns, which set up how multiple concurrently running tasks on processing units (threads for shared memory, processes for clusters) coordinate to complete the parallel computation desired.
CPU Architecture patterns, which are always embedded into the parallel software libraries because they are directly related to how a program is executed on the operating system of the machine with a given architecture. Both types of parallel hardware that we have mentioned so far (Shared memory machines and Clusters) are inherently multiple-instruction, multiple data (MIMD) architectures. This means any machine instruction can be executing in a processing unit (thread or process) simultaneously on the same or different data elements in memory.
We will concentrate on the Coordination Patterns in code the examples in the following chapters, since those are visible to programmers.
Most PDC programs use one of two major coordination patterns:
message passing between concurrent processes on either single multicore machines or clusters of distributed computers, and
mutual exclusion between threads executing concurrently on a single shared memory system.
These two types of computation are often realized using two very popular C/C++ libraries:
MPI, or Message Passing Interface, for message passing on clusters or individual multicore machines.
OpenMP for threaded, shared memory applications.
OpenMP is built on a lower-level POSIX library called Pthreads, which can also be used by itself on shared memory systems.
A third emerging type of parallel implementation involves a hybrid computation that uses both of the above patterns together, using a cluster of computers, each of which executes multiple threads. This type of hybrid program often uses MPI and OpenMP together in one program, which runs on multiple computers in a cluster.
This book is split into chapters of examples. There are examples for shared memory using OpenMP and message passing using MPI, message passing using MPI. (In the future we will include shared memory examples using Pthreads, and hybrid computations using a combination of MPI and OpenMP.)
Most of the examples are illustrated with the C programming language, using standard popular available libraries. In a few cases, C++ is used to illustrate a particular difference in code execution between the two languages or to make use of a C++ BigInt class.
There are many small examples that serve to illustrate a common pattern. They are designed for you to try compiling and running on your own to see how they work. For each example, there are comments within the code to guide you as you try them out. In many cases, there may be code snippets that you can comment and/or uncomment to see how the execution of the code changes after you do so and re-compile it.
Depending on you interest, you can now explore OpenMP Patternlets or MPI Patternlets in the next two chapters.