
CHAPTER 3: Running Loops in Parallel¶
Next we will consider a program that has a loop in it. An iterative for loop is a remarkably common pattern in all programming, primarily used to perform a calculation N times, often over a set of data containing N elements, using each element in turn inside the for loop.
If there are no dependencies between the iterations (i.e. the order of them is not important), then the code inside the loop can be split between forked threads. However, the programmer must first decide how to partition the work between the threads. Specifically, how many and which iterations of the loop will each thread complete on its own?
The data decomposition pattern describes the way how work is distributed across multiple threads. This chapter presents two patternlets,
parallelLoop-equalChunks and parallelLoop-chunksOf1, that describe two common data decomposition strategies.
3.1 Parallel Loop, Equal Chunks¶
Let’s next visit the parallelLoop-equalChunks directory. You can navigate to this directory directly from the spmd
directory by using the following command (don’t forget to use the Tab key to complete the typing for you):
cd ../parallelLoop-equalChunks
Running ls on this directory reveals two new files:
MakefileparallelLoopEqualChunks.c
Let’s study the code in parallelLoopEqualChunks.c in greater detail:
1/* parallelLoopEqualChunks.c
2 * ... illustrates the use of OpenMP's default parallel for loop in which
3 * threads iterate through equal sized chunks of the index range
4 * (cache-beneficial when accessing adjacent memory locations).
5 *
6 * Joel Adams, Calvin College, November 2009.
7 *
8 * Usage: ./parallelLoopEqualChunks [numThreads]
9 *
10 * Exercise
11 * - Compile and run, comparing output to source code
12 * - try with different numbers of threads, e.g.: 2, 3, 4, 6, 8
13 */
14
15#include <stdio.h> // printf()
16#include <stdlib.h> // atoi()
17#include <omp.h> // OpenMP
18
19int main(int argc, char** argv) {
20 const int REPS = 16;
21
22 printf("\n");
23 if (argc > 1) {
24 omp_set_num_threads( atoi(argv[1]) );
25 }
26
27 #pragma omp parallel for
28 for (int i = 0; i < REPS; i++) {
29 int id = omp_get_thread_num();
30 printf("Thread %d performed iteration %d\n",
31 id, i);
32 }
33
34 printf("\n");
35 return 0;
36}
The omp parallel for pragma on line 27 directs the compiler to do the following:
Generate a team of threads (default is equal to the number of cores)
Assign each thread an equal number of iterations (a chunk) of the for loop.
At the end of the scope of the for loop, join all the theads back to a single-threaded process.
As in our previous example, the code up to line 27 is run serially. The code that is in the scope of the
omp parallel for pragma (defined by the for loop) is run in parallel, with a subset of iterations assigned to
each thread. After the implicit join on line 32,
the program once again is a single-threaded process that executes serially to completion.
In the above program, REPS is set to 16. If the program is run with 4 threads, then each thread
gets 4 iterations of the loop (see illustration below):
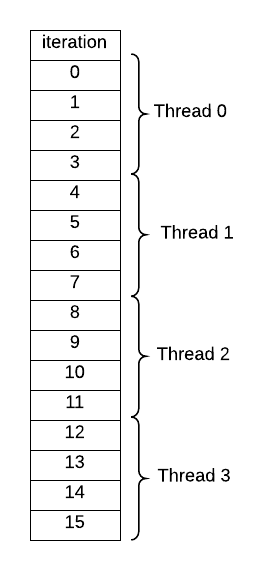
Try It Out¶
Compile and run the program using the following command:
make
./parallelLoopEqualChunks 4
- Iterations are assigned round-robin (iterations 0,4,8,12 go to thread 0; iterations 1,5,9,13 goes to thread 1; iterations 2,6,10,14 go to thread 2, iterations 3,7,11,15 go to thread 3)
- Not quite. Take a closer look at the program output. What do you see?
- Groups of iterations are assigned to a thread (iterations 0-3 go thread 0; iterations 4-7 go to thread 1; iterations 8-11 go to thread 2; iterations 12-15 go to thread 3)
- Correct! Even though the threads print out of order, each thread serially runs the chunk of iterations assigned to it.
- Something else.
- Take a closer look at the output of the program. It is one of the listed options.
Q-1: Try running the program a few times with 4 threads (the up-arrow key will help make this easier). How are iterations assigned to the loop?
Unequal Iterations¶
Sometimes, the number of iterations that a loop runs is not equally divisible by the number of threads.
- All the extra iterations go to a single thread.
- Not quite, though it may appear this way if you only ran the program on 3 and 5 threads. Try running on 6 threads. What do you see?
- The extra iterations are evenly distributed over the threads (each thread still computes its assigned chunk)
- Correct! OpenMP will do its best to ensure that each thread performs an equual amount of work. This is known as load balancing.
- Something else.
- Try running the program a few times. It is one of the listed options above!
Q-2: Try running the program a few times with 3,5, and 6 threads (the up-arrow key will help make this easier). What happens to the extra iterations?
The equal-chunk decomposition patternlet is especially useful in the following scenarios:
Each iteration of the loop takes the same amount of time to finish
The loop involves accesses to data in consecutive memory locations (e.g. an array), allowing the program to take advantage of spatial locality.
3.2 Parallel Loop, Chunks of 1¶
In some cases, it makes sense to have iterations assigned to threads in “round-robin” style. In other words, iteration 0 goes to thread 0, iteration 1 goes to thread 1, iteration 2 goes to thread 2, and so on.
Let’s look at the code example in the parallelLoop-chunksOf1 directory. You can visit this directory from the parallelLoopEqualChunks
directory by executing the following command:
cd ../parallelLoop-chunksOf1
Running the ls command in this new directory reveals the following files:
MakefileparallelLoopChunksOf1.c
Let’s take a closer look at the parallelLoopChunksOf1.c file:
1/* parallelLoopChunksOf1.c
2 * ... illustrates how to make OpenMP map threads to
3 * parallel loop iterations in chunks of size 1
4 * (use when not accesssing memory).
5 *
6 * Joel Adams, Calvin College, November 2009.
7 *
8 * Usage: ./parallelLoopChunksOf1 [numThreads]
9 *
10 * Exercise:
11 * 1. Compile and run, comparing output to source code,
12 * and to the output of the 'equal chunks' version.
13 * 2. Uncomment the "commented out" code below,
14 * and verify that both loops produce the same output.
15 * The first loop is simpler but more restrictive;
16 * the second loop is more complex but less restrictive.
17 */
18
19#include <stdio.h>
20#include <omp.h>
21#include <stdlib.h>
22
23int main(int argc, char** argv) {
24 const int REPS = 16;
25
26 printf("\n");
27 if (argc > 1) {
28 omp_set_num_threads( atoi(argv[1]) );
29 }
30
31 #pragma omp parallel for schedule(static,1)
32 for (int i = 0; i < REPS; i++) {
33 int id = omp_get_thread_num();
34 printf("Thread %d performed iteration %d\n",
35 id, i);
36 }
37
38/*
39 printf("\n---\n\n");
40 #pragma omp parallel
41 {
42 int id = omp_get_thread_num();
43 int numThreads = omp_get_num_threads();
44 for (int i = id; i < REPS; i += numThreads) {
45 printf("Thread %d performed iteration %d\n",
46 id, i);
47 }
48 }
49*/
50 printf("\n");
51 return 0;
52}
The code up to line 37 is near identical to the previous program. The difference is the pragma on
line 31. The omp parallel for pragma has a new schedule clause which specifies the way iterations
should be assigned to threads. The static keyword indicates that the the compiler should assign work
to each thread at compile time (a static scheduling policy). The 1 indicates that the chunk size should
be 1 iteration. Therefore, the above code would have 16 total chunks.
In the case where the number of chunks exceed the number of theads, each successive chunk is assigned to a thread in round-robin fashion.
Try It Out¶
Similar to the other examples, you can make the program and run it as follows:
make
./parallelLoopChunksOf1 4
- The iterations now are assigned to each thread in round-robin fashion.
- Correct! While iterations are still getting statically assigned to threads, they are getting assigned in round-robin fashion.
- There is no change (Thread 0 gets iterations 0-3, Thread 1 gets iterations 4-7, etc.)
- Nope. Try and run the program.
- Something else.
- Nope, it is one of the listed options above!
Q-3: Try running the program a few times with 4 ,5, and 6 threads (the up-arrow key will help make this easier). What’s different in the way iterations are assigned?
Some equivalent code¶
If you carefully looked at the above code file, you would have noticed some code commented out starting on line 38:
38/*
39 printf("\n---\n\n");
40 #pragma omp parallel
41 {
42 int id = omp_get_thread_num();
43 int numThreads = omp_get_num_threads();
44 for (int i = id; i < REPS; i += numThreads) {
45 printf("Thread %d performed iteration %d\n",
46 id, i);
47 }
48 }
49*/
This code shows how the round-robin scheduling approach could be achieved with using just the omp parallel pragma. To understand how this
works, pay close attention to the for loop on line 44. Each thread initializes its loop with its thread id, continues until it exceeds REPS iterations,
incrementing by the number of threads each iteration. Uncommenting and running this code should therefore result in each iteration of the for loop being assigned to each thread in round-robin fashion.
- The two versions behave differently.
- Not quite; carefully observe the program. Remember, it doesn't matter if the iterations are out of order. What matters is what iterations are assigned to which thread.
- The two versions behave the same.
- Correct!
Q-4: Uncomment the code between lines 38-49, and recompile and rerun your program. How similar is this approach to the previous one that uses the omp parallel for pragma with the
schedule(static, 1) clause?
Dynamic Scheduling¶
In some cases, it is beneficial for the assignment of loop iterations to occur at run-time. This is especially useful when each iteration of the loop can take a different amount of time. Dynamic scheduling, or assigning iterations to threads at run time, allows threads that have finished work to start on new work, while letting threads that are still busy continue to work in peace.
To employ a dynamic scheduling policy, replace the static keyword in the schedule clause on line 31 with the keyword dynamic.
- The two versions behave differently.
- Correct! It's important to note that while the iterations of the loop contain the different amounts of work, the use of the dynamic keyword does not have a significant impact on performance. However, we will see a scenario in a few chapters where the dynamic keyword will really make a difference.
- The two versions behave the same.
- Not quite; carefully observe the program by running it a few times. Remember, it doesn't matter if the iterations are out of order. What matters is what iterations are assigned to which thread.
Q-5: Recomment the code between lines 38-49, and change the static keyword to dynamic on line 31. How similar is this approach to the previous one that uses the static keyword in the schedule clause?