2.4 Other Communication Patterns¶
There are many cases when a master process obtains or creates data that needs to be sent or received from all the other processes. In this section, we will discuss some special communication constructs specifically for those purposes.
Broadcast¶
A broadcast sends data from one process to all other processes. A common use of boradcasting is to send user input to all the processes in a parallel program, as shown in the program below:
Program file: 09broadcastUserInput.py
from mpi4py import MPI
import sys
# Determine if user provided a string to be broadcast.
# If not, quit with a warning.
def checkInput(id):
numArguments = len(sys.argv)
if numArguments == 1:
#no extra argument was given- master warns and all exit
if id == 0:
print("Please add a string to be broadcast from master to workers")
sys.exit()
def main():
comm = MPI.COMM_WORLD
id = comm.Get_rank() #number of the process running the code
numProcesses = comm.Get_size() #total number of processes running
myHostName = MPI.Get_processor_name() #machine name running the code
if numProcesses > 1 :
checkInput(id)
if id == 0: # master
#master: get the command line argument
data = sys.argv[1]
print("Master Process {} of {} on {} broadcasts \"{}\""\
.format(id, numProcesses, myHostName, data))
else :
# worker: start with empty data
data = 'No data'
print("Worker Process {} of {} on {} starts with \"{}\""\
.format(id, numProcesses, myHostName, data))
#initiate and complete the broadcast
data = comm.bcast(data, root=0)
#check the result
print("Process {} of {} on {} has \"{}\" after the broadcast"\
.format(id, numProcesses, myHostName, data))
else :
print("Please run this program with the number of processes \
greater than 1")
########## Run the main function
main()
To run the above example use the following command:
python run.py ./09broadcastUserInput.py N dataString
Here the N signifies the number of processes to start up in MPI, which must be greater than one. The dataString must be supplied and represents the string that will be broadcast from the master process to the workers.
For example, in this special instance, you can send a string with spaces and other special characters it it in it like this:
python run.py ./09broadcastUserInput.py 2 "hello\ world\!"
Exercise:
Run, using N = from 1 through 8 processes, with a string of your choosing.
Find the place in this code where the data is being broadcast to all of the processes. Match the prints to the output you observe when you run it.
Broadcasting a list¶
It is also possible to broadcast more complex data structures, like a list. The following program illustrates how to broadcast a list to every process:
Program file: 11broadcastList.py
from mpi4py import MPI
import numpy as np
def main():
comm = MPI.COMM_WORLD
id = comm.Get_rank() #number of the process running the code
numProcesses = comm.Get_size() #total number of processes running
myHostName = MPI.Get_processor_name() #machine name running the code
if numProcesses > 1 :
if id == 0: # master
#master: generate a dictionary with arbitrary data in it
data = np.array(range(numProcesses))
print("Master Process {} of {} on {} broadcasts {}"\
.format(id, numProcesses, myHostName, data))
else :
# worker: start with empty data
data = None
print("Worker Process {} of {} on {} starts with {}"\
.format(id, numProcesses, myHostName, data))
#initiate and complete the broadcast
data = comm.bcast(data, root=0)
#check the result
print("Process {} of {} on {} has {} after the broadcast"\
.format(id, numProcesses, myHostName, data))
else :
print("Please run this program with the number of processes greater than 1")
########## Run the main function
main()
To run the above example use the following command (N signifies the number of processes):
python run.py ./11broadcastList.py N
Exercise:
Run, using N = from 1 through 8 processes.
Scatter and Gather¶
There are often cases when each process can work on some portion of a larger data structure. This can be carried out by having the master process maintain the larger structure and send parts to each of the worker processes, keeping part of the structure on the master. Each process then works on their portion of the data, and then the master can get the completed portions back.
This is so common in message passing parallel processing that there are two special collective communication functions called Scatter() and Gather() that handle this.
The mpi4py Scatter function, with a capital S, can be used to send portions of a larger array on the master to the workers, like this:
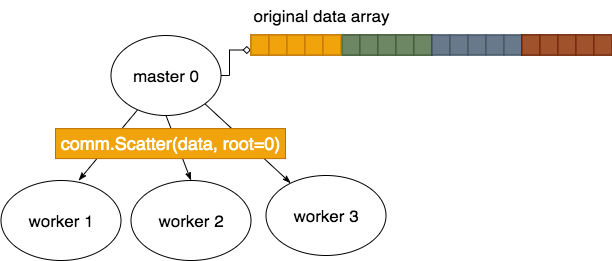
The result of doing this then looks like this, where each process has a portion of the original that they can then work on:
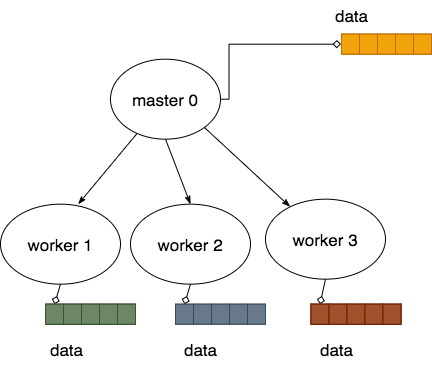
The reverse of this process can be done using the Gather function.
In this example, a 1-D array is created by the master, then scattered, using Scatter (capital S). After each smaller array used by each process is changed, the Gather (capital G) function brings the full array with the changes back into the master.
Note
In the code below, note how all processes must call the Scatter and Gather functions.
Program file: 16ScatterGather.py
from mpi4py import MPI
import numpy as np
# Create a 1D array to be scattered.
def genArray(numProcesses, numElementsPerProcess):
data = np.linspace(1, #start
numProcesses*numElementsPerProcess, #stop
numElementsPerProcess*numProcesses, #total elements
dtype='u4') # 4-byte unsigned integer data type
return data
def timesTen(a):
return(a*10);
def main():
comm = MPI.COMM_WORLD
id = comm.Get_rank() #number of the process running the code
numProcesses = comm.Get_size() #total number of processes running
myHostName = MPI.Get_processor_name() #machine name running the code
# in mpi4py, the uppercase Scatter method works on arrays generated by
# numpy routines.
#
# Here we will create a single array designed to then scatter 3 elements
# of it in a smaller array to each process.
numDataPerProcess = 3
if id == 0:
data = genArray(numProcesses, numDataPerProcess)
#genListOfLists(numElements)
print("Master {} of {} on {} has created array: {}"\
.format(id, numProcesses, myHostName, data))
else:
data = None
print("Worker Process {} of {} on {} starts with {}"\
.format(id, numProcesses, myHostName, data))
#scatter one small array from a part of the large array
# on node 0 to each of the processes
smallerPart = np.empty(numDataPerProcess, dtype='u4') # allocate space for result on each process
comm.Scatter(data, smallerPart, root=0)
if id == 0:
print("Master {} of {} on {} has original array after Scatter: {}"\
.format(id, numProcesses, myHostName, data))
print("Process {} of {} on {} has smaller part after Scatter {}"\
.format(id, numProcesses, myHostName, smallerPart))
# do some work on each element
newValues = timesTen(smallerPart)
print("Process {} of {} on {} has smaller part after work {}"\
.format(id, numProcesses, myHostName, newValues))
# All processes participate in gathering each of their parts back at
# process 0, where the original data is now overwritten with new values
# from eqch process.
comm.Gather(newValues, data, root=0)
if id == 0:
print("Master {} of {} on {} has new data array after Gather:\n {}"\
.format(id, numProcesses, myHostName, data))
########## Run the main function
main()
Example usage:
python run.py ./16ScatterGather.py N
Exercises:
Run, using N = from 2 through 8 processes.
If you want to study the numpy part of the code, look up the numpy method
linspace()used ingenArray().
Applying Gather to PopulateArray¶
Let’s use the Gather() function to simplify the code in the PopulateArray program. The revised code is shown below:
Program file: PopulateArrayGather.py
from mpi4py import MPI
import numpy as np
#array size
N = 2000000
def populateArray(rank, nprocs):
nElems = N/nprocs #number of elemes to generate
isTail = N % nprocs
start = rank*nElems
end = (rank+1)*nElems
if rank == (nprocs-1) and isTail > 0:
end = N
length = end-start
local_array = np.empty(length)
for i in range(length):
local_array[i] = 1+start+i
return local_array
def main():
comm = MPI.COMM_WORLD
myId = comm.Get_rank()
numProcesses = comm.Get_size()
#SPMD pattern
local = populateArray(myId, numProcesses) #generate an empty array of size N
if myId == 0: #initialize global array on master process only
global_array = np.empty(N)
else:
global_array = None
#gather the local results into global_array
comm.Gather(local, global_array, root=0)
if myId == 0:
#print out final array
total = sum(global_array)
print(total)
print((N*(N+1)/2))
########## Run the main function
main()
Notice that the Send/Receive pattern used in the Point-to-Point communication section have now been replaced with
a single comm.Gather() statement. Additional code however is needed to initialize the global array that holds
the final results.
Run this code using the following command (N is the number of processes):
python run.py ./populateArrayGather.py N
Even as we increase the number of processes, the result stays the same.
Exercises
Modify the PopulateArrayGather program to do array addition. Each processor should compute a local sum of the array it produces. The global array should be the length of the number of processes, since the
Gather()function is gathering a number of sums.Modify the Integration example frome earlier to use the
Gather()function.
Reduction¶
There are often cases when every process needs to complete a partial result of an overall computation. For example if you want to process a large set of numbers by summing them together into one value (i.e. reduce a set of numbers into one value, its sum), you could do this faster by having each process compute a partial sum, then have all the processes communicate to add each of their partial sums together.
This is so common in parallel processing that there is a special collective communication function called reduce that does just this.
The type of reduction of many values down to one can be done with different types of operators on the set of values computed by each process.
Reduce all values using sum and max¶
In this example, every process computes the square of (id+1). Then all those values are summed together and also the maximum function is applied.
Program file: 12reduction.py
from mpi4py import MPI
def main():
comm = MPI.COMM_WORLD
id = comm.Get_rank() #number of the process running the code
numProcesses = comm.Get_size() #total number of processes running
myHostName = MPI.Get_processor_name() #machine name running the code
square = (id+1) * (id+1)
if numProcesses > 1 :
#initiate and complete the reductions
sum = comm.reduce(square, op=MPI.SUM)
max = comm.reduce(square, op=MPI.MAX)
else :
sum = square
max = square
if id == 0: # master/root process will print result
print("The sum of the squares is {}".format(sum))
print("The max of the squares is {}".format(max))
########## Run the main function
main()
Example usage:
python run.py ./12reduction.py N
Exercises:
Run, using N = from 1 through 8 processes.
Try replacing MPI.MAX with MPI.MIN(minimum) and/or replacing MPI.SUM with MPI.PROD (product). Then save and run the code again.
Find the place in this code where the data computed on each process is being reduced to one value. Match the prints to the output you observe when you run it.
Reduction on a list of values¶
We can try reduction with lists of values, but the behavior matches Python semantics regarding lists.
Note
There are two ways in Python that you might want to sum a set of lists from each process: 1) concatenating the elements together, or 2) summing the element at each location from each process and placing the sum in that location in a new list. In the latter case, the new list is the same length as the original lists on each process.
Program file: 13reductionList.py
from mpi4py import MPI
# Exercise: Can you explain what this function returns,
# given two lists as input?
def sumListByElements(x,y):
return [a+b for a, b in zip(x, y)]
def main():
comm = MPI.COMM_WORLD
id = comm.Get_rank() #number of the process running the code
numProcesses = comm.Get_size() #total number of processes running
myHostName = MPI.Get_processor_name() #machine name running the code
srcList = [1*id, 2*id, 3*id, 4*id, 5*id]
destListMax = comm.reduce(srcList, op=MPI.MAX)
destListSum = comm.reduce(srcList, op=MPI.SUM)
#destListSumByElement = comm.reduce(srcList, op=sumListByElements)
if id == 0: # master/root process will print result
print("The resulting reduce max list is {}".format(destListMax))
print("The resulting reduce sum list is {}".format(destListSum))
#print("The resulting reduce sum list is {}".format(destListSumByElement))
########## Run the main function
main()
Example usage:
python run.py ./13reductionList.py N
Exercises:
Run, using N = from 1 through 4 processes.
Uncomment the two lines of runnable code that are commented in the main() function. Observe the new results and explain why the MPI.SUM (using the + operator underneath) behaves the way it does on lists, and what the new function called sumListByElements is doing instead.
In this code, try to explain what the function called sumListByElements does. If you are unfamiliar with the zip function, look up what it does.
Returning to the Array Example¶
Let’s return to the problem of array addition, where the goal is to sum all the elements in an array together in parallel. We build on our earlier PopulateArray
program. After populating the array in parallel, we will use the scatter() method first to re-distribute the contents of the global_array to each
process:
#gather the local results into global_array (old code)
comm.Gather(local, global_array, root=0)
#step 2: compute local sums (new code)
#now scatter the global array to each process
comm.Scatter(global_array, local, root=0)
#compute local sums
local_sum = sum(local)
Here, the local array is overwritten with the scattered results of global_array. Each process then computes its local sum (stored in local_sum).
Computing the final total using Gather¶
One way to compute the final total is to use a second invocation of the Gather() function as shown below:
#gather the local results into global_array (old code)
comm.Gather(local, global_array, root=0)
#step 2: compute local sums (new code)
#now scatter the global array to each process
comm.Scatter(global_array, local, root=0)
#compute local sums
local_sum = sum(local)
if myId == 0: #initialize all_sums array on master only
all_sums = np.empty(numProcesses)
else:
all_sums = None
#gather the local sums into all_sums array
comm.Gather(local_sum, all_sums, root=0)
if myId == 0:
#print out final array
finalTotal = sum(all_sums)
print(finalTotal)
print((N*(N+1)/2))
The master process allocates a new array called all_sums, which is then populated by a second Gather() call. Finally, the master process computes
the final total by summing together all the subtotals located in the all_sums array.
Computing the final total using Reduce¶
Recall that the Reduce() function combines all the local values using a common function (i.e. Sum, Max, Min, Prod). Since our goal is to add together
all the elments of our array, we can use the Reduce() function as follows:
#gather the local results into global_array (old code)
comm.Gather(local, global_array, root=0)
#step 2: compute local sums
#now scatter the global array to each process
comm.Scatter(global_array, local, root=0)
#compute local sums (SPMD)
local_sum = sum(local)
#reduction (new change)
finalTotal = comm.reduce(local_sum, op=MPI.SUM)
if myId == 0:
#print out final array
print(finalTotal)
print((N*(N+1)/2))
In addition to being shorter, this code snippet is much simpler than the one employing Gather, as all the master process is doing is printing out the result.
Exercise:
- The version using Gather is faster than the version using Reduce.
- No. Ensure that the Gather version uses Gather to collect the sums.
- Both implementations perform about the same.
- No. Did you time each implementation?
- The version using Reduce is faster than the version using Gather.
- Correct! Not only is version employing Reduce shorter and simpler, it is much faster.
Q-1: Add timing code and compare the performance of array Addition example employing Gather vs. Reduce. How do they compare?
Exercise:
Now modify the integration example to use Reduce(). Compare the performance of the integration example with the earlier one that uses Gather(). Which is faster?